< What is Web Scrapping >
web scraping은 웹 상의 데이터를 추출하는 것을 말한다.
url의 제목과 상단 첫 이미지를 가져와서 페이스북 preview를 보여준다.
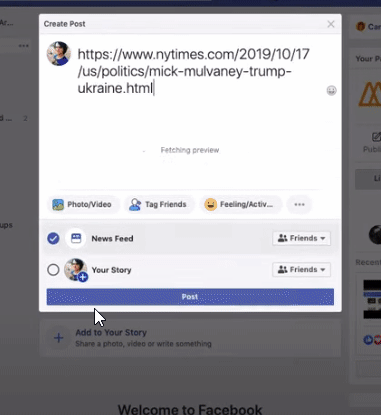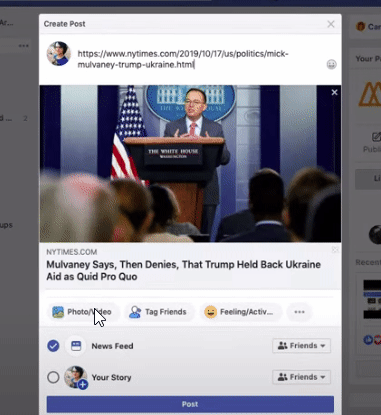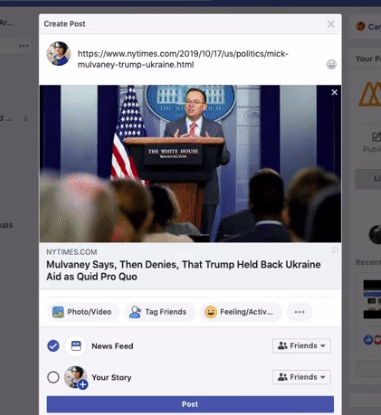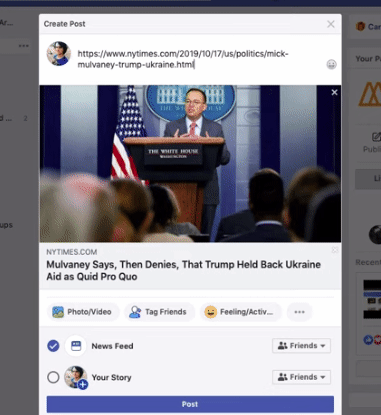
이런걸 scraping이라고 하는데 이것말고도 더 다양하게 쓰일 수 있다.
예를들어 웹사이트에서 휴대폰을 구매하려고 한다고 가정하자.
마켓컬리, ssg, 아마존 이 세 가지 사이트에서 구매를 하려고 고려중이다.
이때 파이썬 스크립트를 만들어서 매 10초마다 매일 그 세 가지 웹사이트에서
휴대폰을 찾아서 웹사이트에 올라온 가격과 할인 등을 파이썬 web scraping으로 알아볼 수 있다.
원하는 정보를 추출할 수 있다.
저명한 여러 언론사에서 정보를 아침마다 scraping 할 수도 있다.
< What are We Building >
Indeed , StackOverflow는 유명한 구인구직 사이트이다.
여기서 정보를 추출해보는것이 이번 프로젝트 목표다.
(등록되어 있는 파이썬 개발자 일자리 정보를 가져올거다.)
가져온 모든 일자리 정보를 엑셀 시트로 옮길거다.
< Navigating with Python >
먼저 파이썬을 써서 두 사이트로 접근할거다.
그런 다음 페이지가 몇 개인지 알아야 한다.
Indeed부터 scraping 해보자.
일단 Indeed부터 정보를 가져오고 stackoverflow를 들어가볼거다.
그리고 마지막에 모든 결과를 엑셀 시트에 보여줄거다.
requests 는 파이썬에서 요청을 만드는 기능을 모아 놓은거다.
import requests 라고 쓰고 url 요청을 만든다.
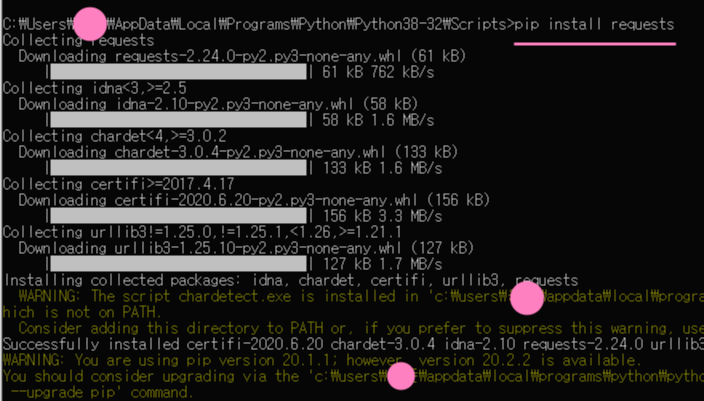
하지만 사용하기전에 requests를 설치부터 해야된다.

cmd로 파이썬 설치경로로 이동한다. (Scripts 폴더까지 경로 이동을 해야 설치가 가능하다.)
경로 -> C:\Users\hello\AppData\Local\Programs\Python\Python38-32\Scripts>
설치명령어 -> pip install requests
Indeed 에서 파이썬을 검색한뒤 맞춤검색으로 들어가서 아래와 같이 설정한다.

그 다음 url 주소를 복사해서 아래와 같이 코드를 작성한다.
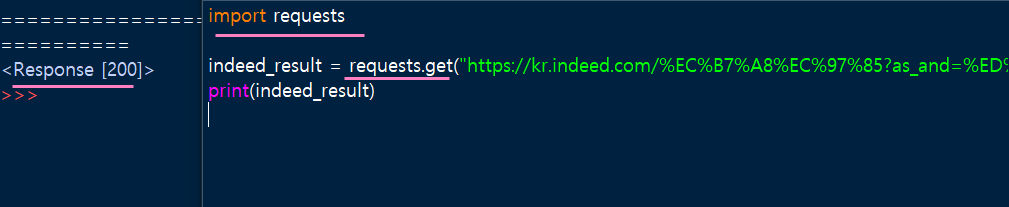
indeed_result.text 를 출력하면 html 전부를 가져온다.
저 html 정보에서 추출하는거다.
우리가 가져올 정보는 페이지 숫자들이다.
Beautiful Soup이라는 라이브러리를 사용할거다.
https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup: We called him Tortoise because he taught us.
www.crummy.com
html에서 정보를 추출하기에 정말 좋은 package이다.
사용하기에 앞서 설치를 먼저 해보자.
pip install beautifulsoup4

※ 본 포스팅은 개인 공부 기록을 목적으로 남긴 글이며 본 사실과 다른 부분이 있다면 과감하게 지적 부탁드립니다.
'Python > Python으로 웹 스크래퍼 만들기' 카테고리의 다른 글
| [SCRAPPER Clone] 2. Extracting Indeed Pages (0) | 2020.09.02 |
|---|---|
| [Python] 3. Conditionals / Modules (0) | 2020.08.31 |
| [Python] 2. Function / Returns / Keyworded Arguments (0) | 2020.08.30 |
| [Python] 1. Data Types / Lists / Tuples and Dicts (0) | 2020.08.30 |
| [Python] 0. INTRODUCTION (0) | 2020.08.30 |




댓글